








































Machine Learning đang trở thành một công nghệ cốt lõi trong kỷ nguyên số, mang lại những bước tiến vượt bậc trong nhiều lĩnh vực từ sản xuất, dịch vụ đến y tế, tài chính. Vậy Machine Learning là gì? Trong bài viết này, MISA AMIS sẽ giúp bạn hiểu rõ hơn về khái niệm, phân loại, cũng như cách thức hoạt động và ứng dụng của Machine Learning trong thực tiễn.




| [Tặng bạn eBook] CẤY GEN AI CHO DOANH NGHIỆP |
1. Machine Learning là gì?
Machine Learning hay còn gọi là Học máy, là một nhánh của trí tuệ nhân tạo (AI) và khoa học máy tính, tập trung vào việc sử dụng dữ liệu và các thuật toán để mô phỏng cách con người học tập, sau đó dần cải thiện độ chính xác theo thời gian. (theo IBM)
Machine Learning bắt nguồn từ những năm 1950 khi Arthur Samuel – một nhà khoa học máy tính tại IBM, lần đầu tiên sử dụng thuật ngữ này để mô tả khả năng máy tính học từ kinh nghiệm mà không cần lập trình cụ thể. Qua các thập kỷ, Machine Learning phát triển với các tiến bộ như thuật toán “nearest neighbor” trong những năm 1960 và mạng nơ-ron vào những năm 1980. Đến năm 2009, dự án ImageNet đã đánh dấu một bước ngoặt quan trọng trong lĩnh vực này.

Học máy đóng vai trò quan trọng trong việc tự động hóa quy trình và nâng cao hiệu quả hoạt động của doanh nghiệp. Nhờ Machine Learning, các doanh nghiệp có thể dự đoán chính xác xu hướng thị trường, cá nhân hóa trải nghiệm khách hàng, tối ưu hóa dịch vụ, đặc biệt trong các lĩnh vực như tài chính và y tế.
Bên cạnh đó, Machine Learning còn là nền tảng cho các công nghệ tiên tiến như trí tuệ nhân tạo hay xe tự lái, thúc đẩy sự đổi mới và tạo ra giá trị trong nhiều ngành công nghiệp.
2. Machine Learning hoạt động như thế nào?
Sau khi đã hiểu Machine Learning là gì, chúng ta cần đi sâu vào cách thức mà công nghệ này hoạt động để có thể ứng dụng vào thực tế.
Machine Learning hoạt động dựa trên nguyên tắc cho phép máy tính học hỏi từ dữ liệu mà không cần lập trình chi tiết cho từng tác vụ. Quá trình này có thể được chia thành các bước cơ bản sau:
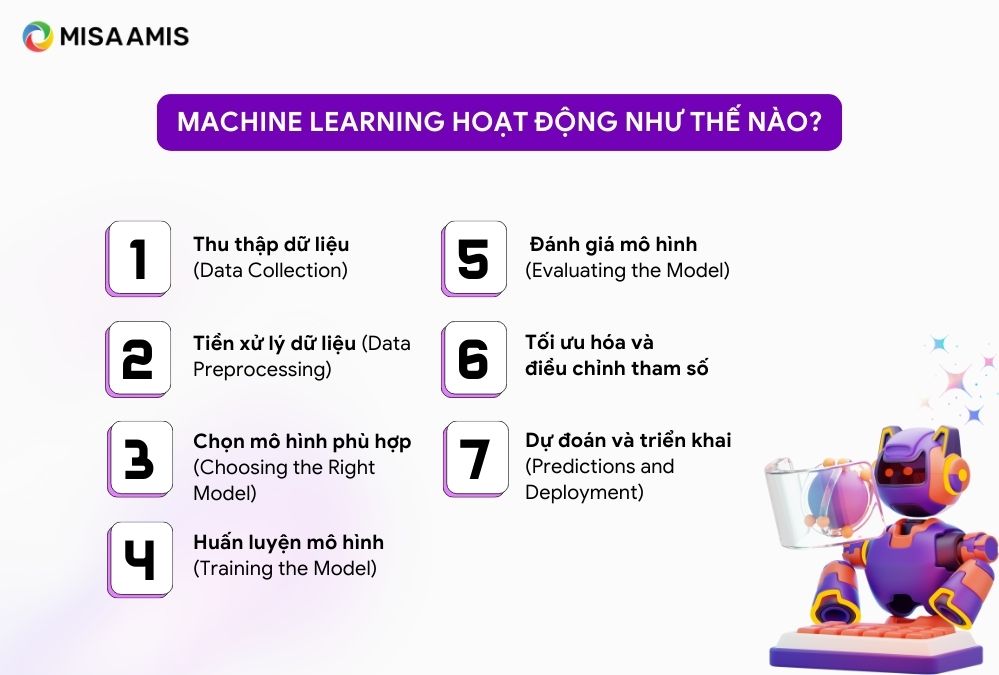
Bước 1: Thu thập dữ liệu (Data Collection)
Bước đầu tiên là thu thập dữ liệu từ các nguồn khác nhau như cơ sở dữ liệu, cảm biến, giao dịch người dùng, mạng xã hội… Chất lượng và số lượng dữ liệu rất quan trọng vì chúng ảnh hưởng trực tiếp đến hiệu suất của mô hình. Dữ liệu phải đủ lớn và đa dạng để mô hình có thể học và đưa ra dự đoán chính xác trong nhiều tình huống khác nhau.
Bước 2: Tiền xử lý dữ liệu (Data Preprocessing)
Dữ liệu thô có thể chứa các giá trị thiếu, không nhất quán hoặc lỗi. Tiền xử lý bao gồm các bước làm sạch dữ liệu như loại bỏ giá trị ngoại lệ, xử lý giá trị thiếu, chuyển đổi dữ liệu về dạng phù hợp (chuẩn hóa, mã hóa danh mục…). Mục tiêu là chuẩn bị dữ liệu để mô hình có thể dễ dàng hiểu và học từ đó.
Bước 3: Chọn mô hình phù hợp (Choosing the Right Model)
Sau khi dữ liệu được xử lý, bước tiếp theo là chọn mô hình Machine Learning phù hợp. Ví dụ, nếu bài toán của bạn yêu cầu phân loại (tức là chia dữ liệu thành các nhóm khác nhau), bạn có thể chọn các mô hình như cây quyết định hoặc máy vector hỗ trợ (Support Vector Machine).
Nếu bài toán cần dự đoán một giá trị liên tục (như giá nhà, doanh thu), bạn sẽ sử dụng các mô hình như hồi quy tuyến tính. Việc chọn mô hình phụ thuộc vào loại dữ liệu và mục tiêu mà bạn muốn đạt được.
Bước 4: Huấn luyện mô hình (Training the Model)
Mô hình được huấn luyện trên tập dữ liệu mà bạn đã thu thập và chuẩn hóa. Trong quá trình này, mô hình học cách tạo ra dự đoán bằng cách tối ưu hóa các tham số nội bộ sao cho sai số giữa dự đoán và kết quả thực tế là nhỏ nhất. Quá trình huấn luyện thường lặp lại nhiều lần để mô hình học sâu hơn từ dữ liệu.
Bước 5: Đánh giá mô hình (Evaluating the Model)
Sau khi mô hình được huấn luyện, bước đánh giá sẽ kiểm tra hiệu suất của nó cũng như chất lượng của tệp dữ liệu. Các chỉ số như độ chính xác (accuracy), độ nhạy (sensitivity) và F1-score (thước đo cân bằng giữa độ chính xác và khả năng nhận diện) được sử dụng để đánh giá chất lượng của mô hình. Bước này đảm bảo rằng mô hình có thể áp dụng tốt vào các tình huống thực tế.
Bước 6: Tối ưu hóa và điều chỉnh tham số (Hyperparameter Tuning and Optimization)
Ở bước này, mô hình được tối ưu hóa bằng cách điều chỉnh các tham số nhất định, như tốc độ học hoặc cấu trúc mạng nơ-ron để đạt hiệu suất tốt nhất. Mục tiêu là giúp mô hình học đủ từ dữ liệu mà không học quá kỹ (quá khớp – overfitting) hoặc quá sơ sài (dưới khớp – underfitting).
Bước 7: Dự đoán và triển khai (Predictions and Deployment)
Sau khi mô hình đã được tối ưu và kiểm tra kỹ lưỡng, nó được triển khai trong môi trường thực tế để dự đoán trên dữ liệu mới. Mô hình có thể được tích hợp vào hệ thống sản xuất, trang web hoặc ứng dụng để cung cấp các dự đoán hoặc phân tích tự động, từ đó hỗ trợ ra quyết định trong thời gian thực.
3. Các khái niệm cơ bản về Machine Learning cần biết
Để hiểu rõ hơn về cách Machine Learning hoạt động, bạn cần nắm vững một số khái niệm cơ bản, liên quan trực tiếp đến các bước trong quá trình triển khai Machine Learning, cụ thể:

Data Set (Tập dữ liệu)
Tập dữ liệu xuất hiện ở bước 1 – Thu thập dữ liệu. Đây là toàn bộ dữ liệu thô mà bạn sử dụng để huấn luyện và đánh giá mô hình Machine Learning. Tập dữ liệu chứa nhiều Data Point (điểm dữ liệu) khác nhau và là nguồn thông tin chính để mô hình học hỏi.
Data Point (Điểm dữ liệu)
Điểm dữ liệu là các đơn vị dữ liệu riêng lẻ trong tập dữ liệu, thường được xử lý ở bước 2 – Tiền xử lý dữ liệu. Mỗi điểm dữ liệu chứa các thông tin cụ thể liên quan đến bài toán, ví dụ như một dòng dữ liệu trong bảng, một hình ảnh hoặc một mẫu âm thanh.
Training Data và Test Data (Dữ liệu huấn luyện và dữ liệu kiểm tra)
Hai tập dữ liệu này được sử dụng ở bước 4 – Huấn luyện mô hình và bước 5 – Đánh giá mô hình.
- Training Data là phần dữ liệu mà mô hình học từ đó trong quá trình huấn luyện.
- Test Data (hoặc dữ liệu chưa thấy trước đó) là dữ liệu dùng để kiểm tra khả năng của mô hình trong việc dự đoán trên dữ liệu mới.
Features Vector (Vector đặc trưng)
Vector đặc trưng được sử dụng trong bước 3 – Chọn mô hình phù hợp và bước 4 – Huấn luyện mô hình. Đây là danh sách các giá trị đại diện cho các thuộc tính của một điểm dữ liệu mà mô hình sử dụng để học. Ví dụ, trong bài toán dự đoán giá nhà, các đặc trưng có thể bao gồm diện tích, số phòng, vị trí ngôi nhà.
Model (Mô hình)
Mô hình là thuật toán được sử dụng trong bước 4 – Huấn luyện mô hình. Trong quá trình này, mô hình học từ dữ liệu để nhận diện các mẫu và mối quan hệ. Sau đó đến bước 7 – Dự đoán và triển khai, mô hình sẽ dựa trên những kiến thức đã học để thực hiện dự đoán hoặc đưa ra quyết định khi xử lý dữ liệu mới.
Có thể bạn quan tâm: Big Data là gì? Đặc trưng và ứng dụng thực tiễn của Big Data
4. Phân loại Machine Learning
Dựa trên cách thức mô hình học từ dữ liệu, Machine Learning có thể được phân thành ba loại hình chính:

Học có giám sát – Supervised Learning
Đây là một dạng học máy trong đó mô hình được huấn luyện bằng các dữ liệu đã được gắn nhãn. Tức là mỗi dữ liệu đầu vào sẽ đi kèm với một kết quả mong muốn, giúp mô hình học cách dự đoán chính xác dựa trên các ví dụ có sẵn. Khi được áp dụng vào thực tế, mô hình này sẽ điều chỉnh trọng lượng của dữ liệu đầu vào sao cho phù hợp nhất, đảm bảo rằng mô hình không bị quá tải hoặc thiếu thông tin cần thiết.
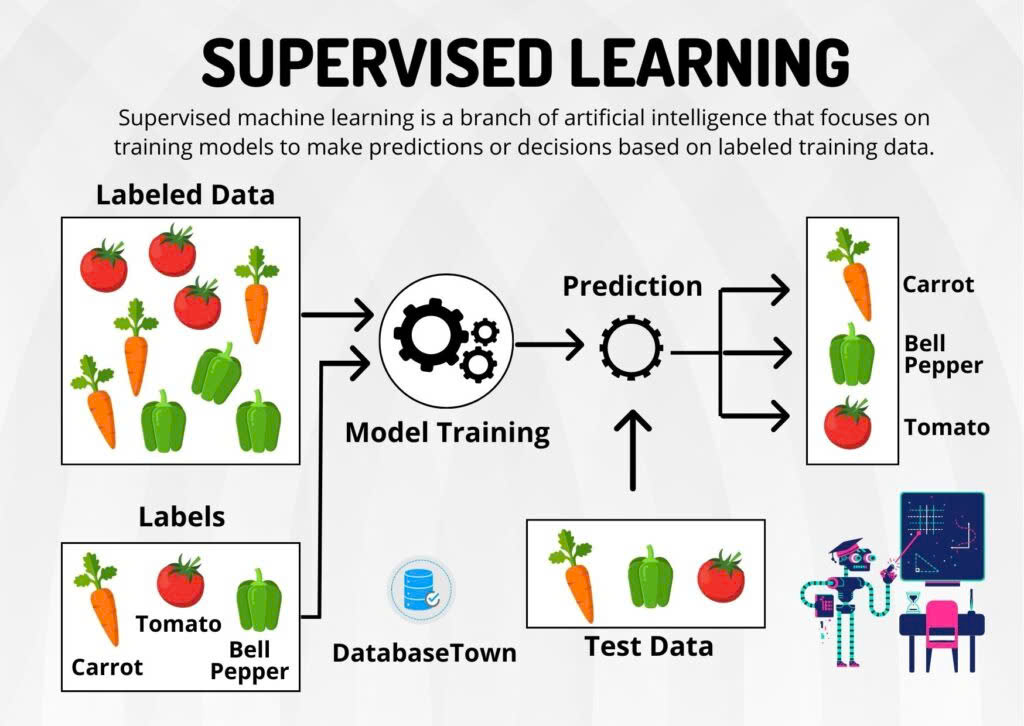
Học có giám sát được sử dụng trong nhiều phương pháp khác nhau như Hồi quy logistic, mạng nơ-ron… Ví dụ về việc phân loại thư rác: mô hình học từ các email đã được gắn nhãn là “thư rác” hoặc “không phải thư rác,” sau đó tự động phân loại các email mới. Trong doanh nghiệp, loại hình này có thể giải quyết nhiều vấn đề quan trọng như dự báo doanh thu, phát hiện gian lận, tối ưu hóa quảng cáo.
Học không giám sát – Unsupervised Learning
Loại hình này khác biệt ở chỗ mô hình sẽ không được cung cấp nhãn dữ liệu. Thay vì dự đoán kết quả dựa trên các ví dụ đã biết, mô hình này tự khám phá các cấu trúc hoặc mẫu ẩn trong dữ liệu. Điều này rất hữu ích trong việc phân nhóm dữ liệu hoặc tìm ra các mối quan hệ mà con người không nhận thấy được.
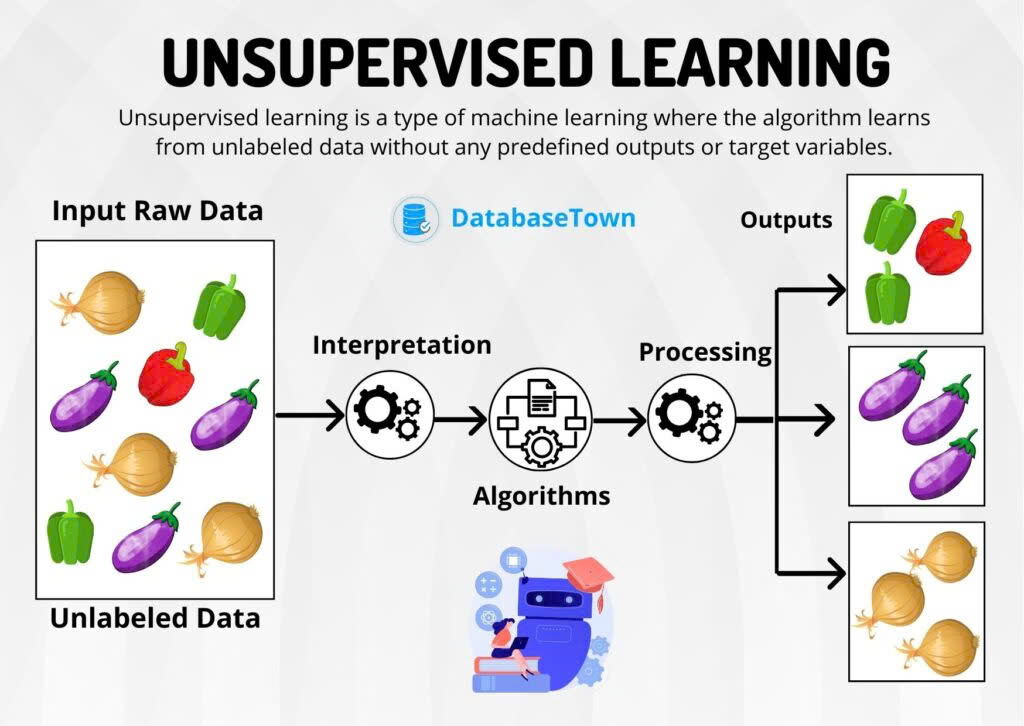
Học không giám sát thường được sử dụng trong việc giảm kích thước dữ liệu nhằm đơn giản hóa mô hình, như phân tích thành phần chính (PCA – Principal Component Analysis) và phân tích giá trị đơn lẻ (SVD – Singular Value Decomposition). Ứng dụng điển hình là việc phân nhóm khách hàng theo hành vi mua sắm mà không cần sự can thiệp của con người, giúp doanh nghiệp tạo các chiến lược marketing hiệu quả hơn.
Học tăng cường – Reinforcement Learning
Học tăng cường là một dạng học máy mà mô hình học qua việc tương tác với môi trường và nhận phản hồi từ hành động của mình. Trong quá trình này, mô hình thực hiện các hành động, nhận thưởng (hoặc bị phạt) từ môi trường, và sử dụng thông tin này để điều chỉnh hành vi của mình nhằm tối đa hóa tổng thưởng qua thời gian.
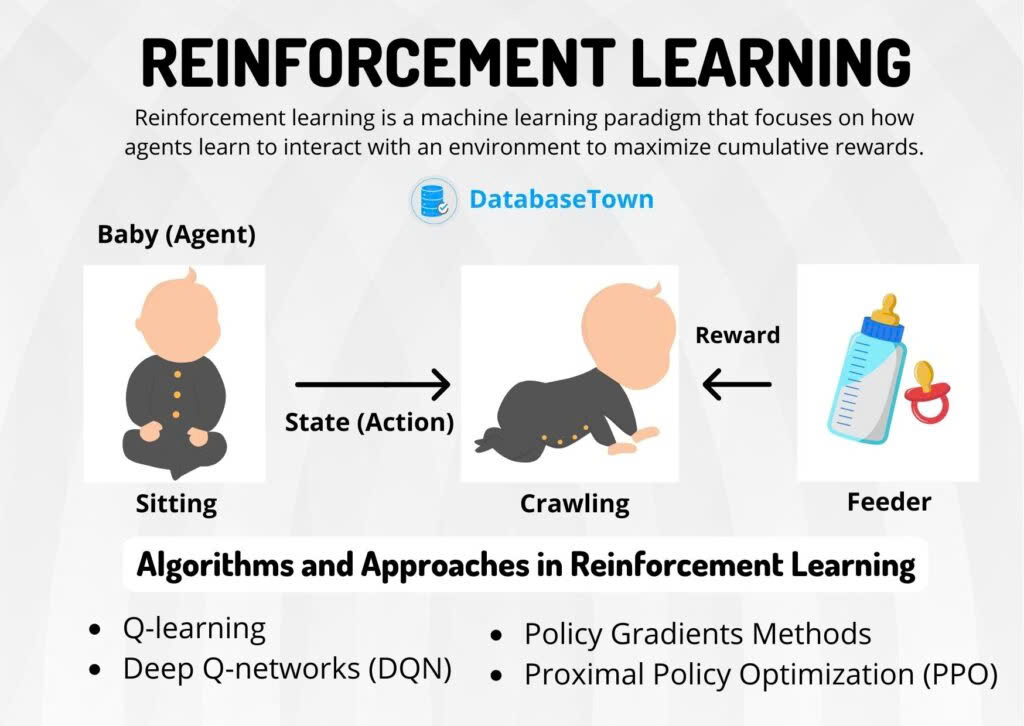
Một ví dụ đơn giản là AI trong trò chơi điện tử: mô hình sẽ thử các hành động khác nhau, học cách chơi tốt hơn bằng cách ghi nhớ những hành động mang lại điểm số cao và tránh những hành động dẫn đến thất bại. Học tăng cường được áp dụng rộng rãi trong các lĩnh vực như robot tự hành, hệ thống đề xuất, đặc biệt là các trò chơi trí tuệ nhân tạo như cờ vua, cờ vây.
Ngoài ra, còn có một số phân loại khác như Học bán giám sát (Semi-supervised Learning) – nơi sử dụng kết hợp dữ liệu có gắn nhãn và không gắn nhãn, và Học tự giám sát (Self-supervised Learning) – một kỹ thuật mới nổi giúp máy móc học từ chính dữ liệu của mình mà không cần nhãn thủ công.

5. Ứng dụng thực tiễn của Machine Learning
Theo một thống kê của G2, GDP toàn cầu dự kiến sẽ tăng 15,7 nghìn tỷ đô la vào năm 2030 nhờ việc ứng dụng Machine Learning. Có thể thấy, Machine Learning không chỉ thay đổi cách các doanh nghiệp hoạt động mà còn đóng góp mạnh mẽ vào sự phát triển kinh tế toàn cầu.
Các ứng dụng thực tiễn của Machine Learning đang ngày càng mở rộng, mang lại những lợi ích vượt trội trong nhiều lĩnh vực khác nhau từ y tế, tài chính đến thương mại điện tử, giao thông. Dưới đây là một số ứng dụng thực tiễn của Machine Learning:
Nhận diện giọng nói
Hay còn được gọi là nhận diện tiếng nói tự động (ASR – Automatic Speech Recognition). Công nghệ này sử dụng xử lý ngôn ngữ tự nhiên (NLP) để chuyển đổi giọng nói của con người thành văn bản. Nhiều thiết bị di động tích hợp tính năng này để hỗ trợ tìm kiếm bằng giọng nói, ví dụ như Siri hay Google Assistant, giúp người dùng thao tác dễ dàng và tiện lợi hơn.
Tự động hóa quy trình bằng robot (RPA)
RPA – Robotic Process Automation sử dụng công nghệ tự động thông minh để thực hiện các tác vụ lặp đi lặp lại, giúp giảm tải công việc thủ công cho con người và tăng hiệu suất làm việc. Trong doanh nghiệp, RPA được sử dụng để tự động hóa các công việc như xử lý hóa đơn, nhập dữ liệu, gửi email tự động.
Dịch vụ khách hàng
Chatbot trực tuyến đang dần thay thế nhân viên chăm sóc khách hàng trong các giai đoạn khác nhau. Các chatbot có thể trả lời những câu hỏi thường gặp (FAQs), cung cấp lời khuyên cá nhân hóa, gợi ý sản phẩm, thậm chí hỗ trợ chọn kích cỡ sản phẩm.
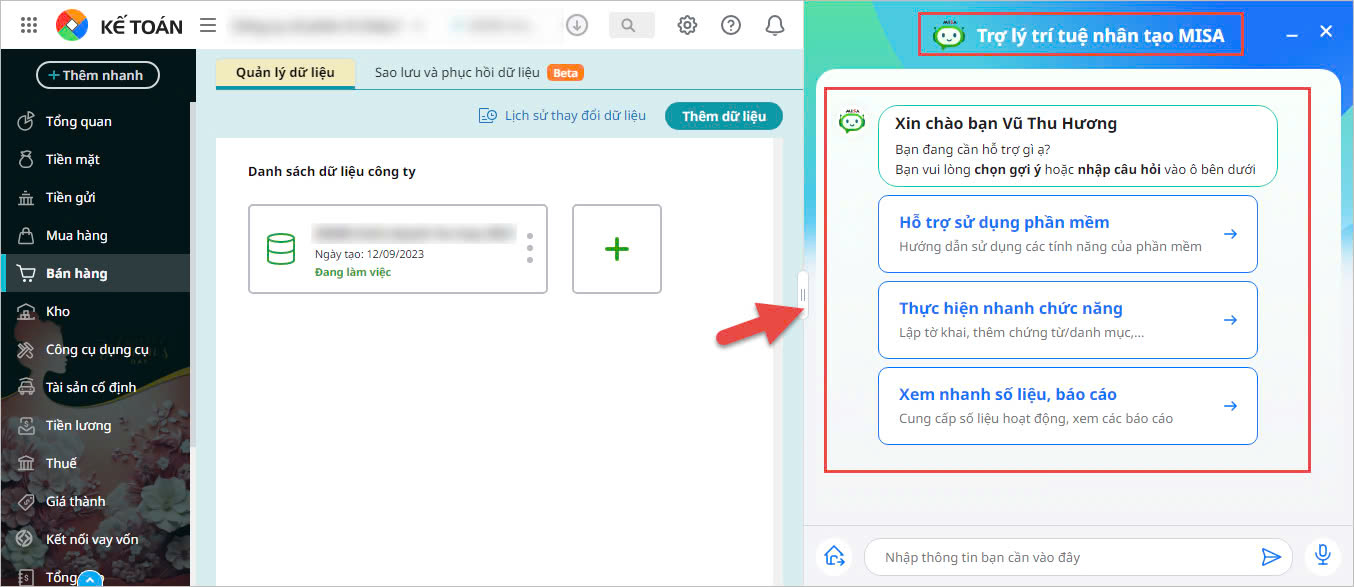
Ví dụ về ứng dụng này có thể thấy ở trợ lý ảo trên các trang thương mại điện tử hoặc trên phần mềm, chẳng hạn như trợ lý trí tuệ nhân tạo MISA AVA được tích hợp trong nền tảng quản trị doanh nghiệp hợp nhất MISA AMIS. Khi người dùng yêu cầu hỗ trợ sử dụng phần mềm, AVA sẽ phản hồi lại bằng các thông tin phù hợp.
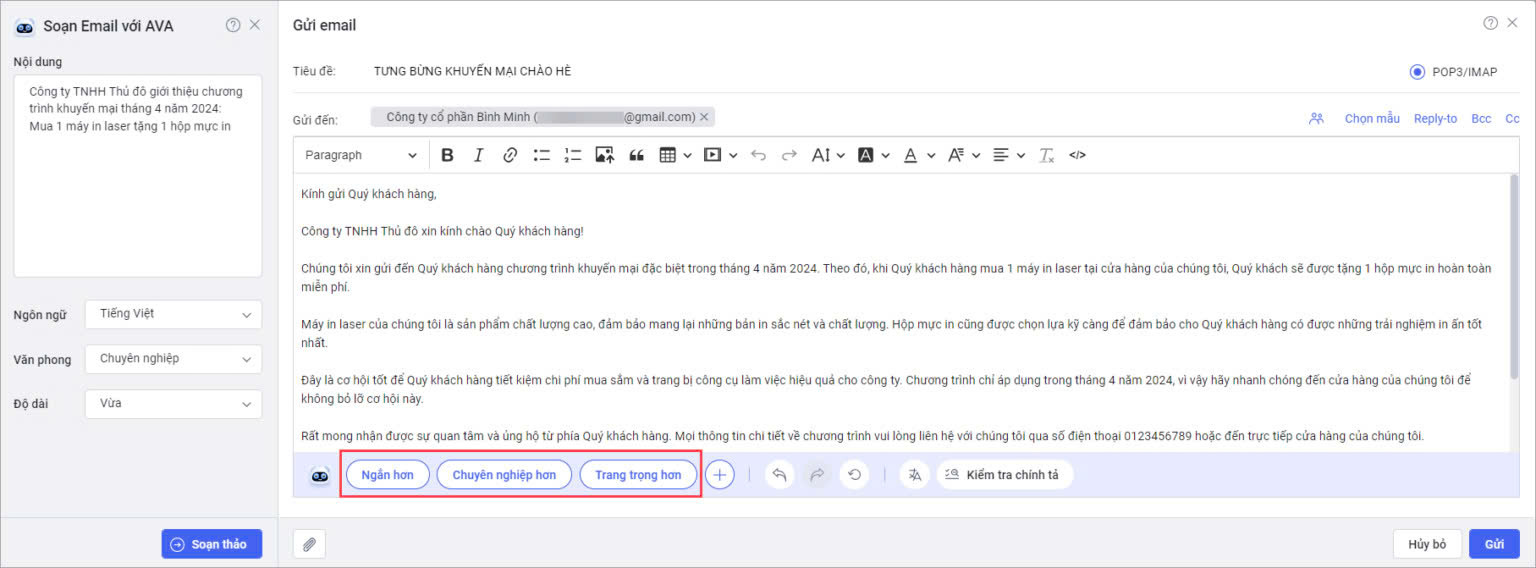
Hay khi cần gửi email cho khách hàng, trợ lý AVA có thể tự động soạn thảo nội dung email hơn tùy theo nhu cầu người dùng. Đồng thời, AVA cũng hỗ trợ kiểm tra và sửa lỗi chính tả trên email góp phần tạo sự chuyên nghiệp khi làm việc với khách hàng.
Trong lĩnh vực kế toán, nếu như trước đây, người dùng phải cần đến 5-6 thao tác mới lấy được báo cáo, thì hiện nay với Trợ lý AVA, chỉ với một câu lệnh bằng văn bản hoặc giọng nói, ngay lập tức giám đốc hoặc kế toán viên sẽ nhận được các báo cáo mong muốn với tốc độ ước tính nhanh gấp 5 lần.
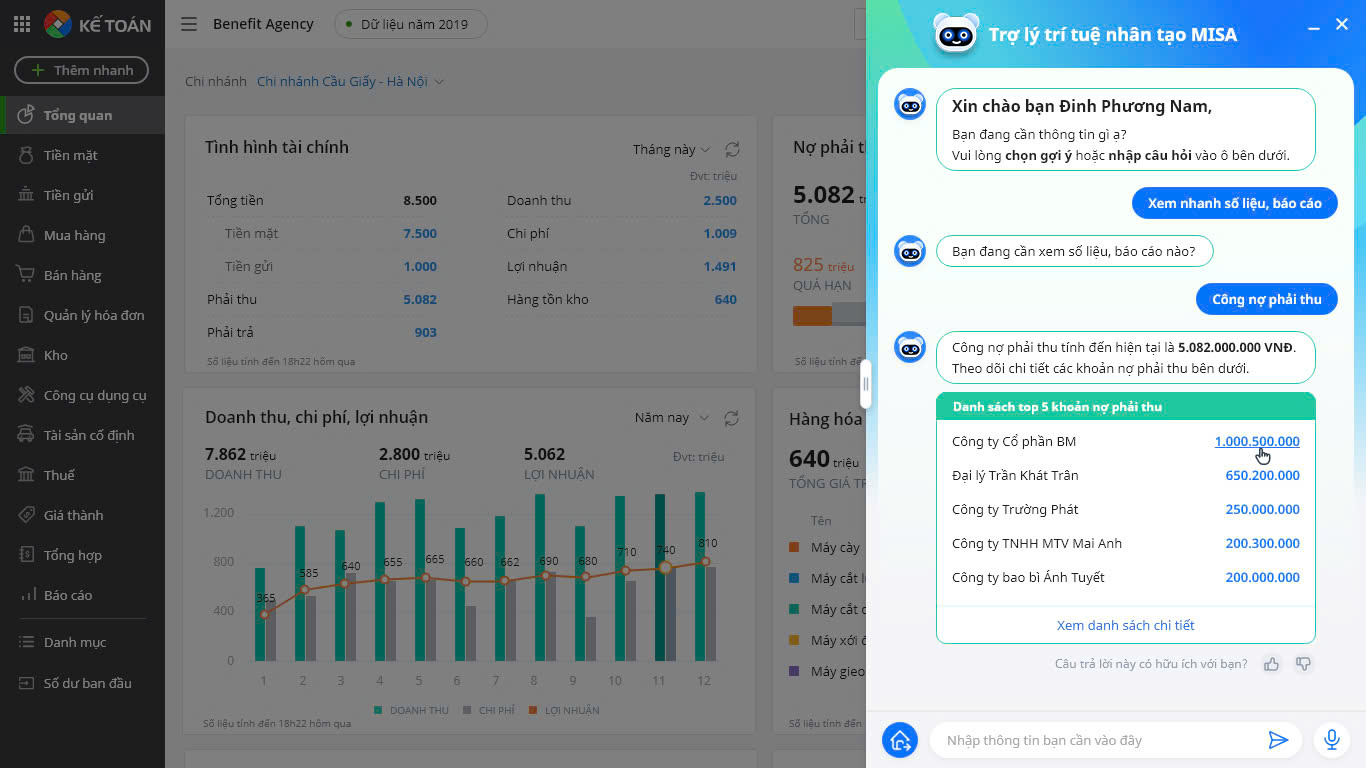
Trợ lý AVA được tích hợp trong MISA AMIS – nền tảng quản lý toàn diện, hỗ trợ doanh nghiệp trong việc thu thập, lưu trữ và phân tích dữ liệu ở cả 4 trụ cột bao gồm Tài chính – Kế toán, Marketing – Bán hàng, Nhân sự, Điều hành.
Dùng thử và khám phá sức mạnh của Trợ lý AVA ngay tại đây:
Phát hiện gian lận
Machine Learning có thể hỗ trợ phát hiện gian lận bằng cách phân tích khối lượng lớn dữ liệu giao dịch, tìm kiếm điểm bất thường hoặc sai lệch so với các tiêu chuẩn đã thiết lập. Chẳng hạn, nếu nhận thấy một giao dịch chuyển tiền quốc tế lớn từ một tài khoản không có lịch sử thực hiện các giao dịch tương tự, nó sẽ đánh dấu giao dịch này là đáng ngờ và gửi cảnh báo đến bộ phận kiểm soát.
Tại châu Âu, tổng giá trị giao dịch gian lận hàng năm trên khắp châu lục này lên tới 1,8 tỷ EUR, khiến nhu cầu về các biện pháp phòng chống gian lận trở nên cấp thiết hơn bao giờ hết. KPMG – hãng kiểm toán đa quốc gia đã kết hợp với Nets – công ty hàng đầu về dịch vụ thanh toán, để phát triển Nets Fraud Ensemble – một giải pháp chống gian lận được hỗ trợ bởi công nghệ AI. Công cụ này có thể ngăn chặn tới 40% các giao dịch gian lận.
Thị giác máy tính (Computer Vision)
Công nghệ này giúp máy tính hiểu và phân tích thông tin từ hình ảnh, video và các đầu vào trực quan khác, sau đó đưa ra hành động thích hợp. Thị giác máy tính được ứng dụng rộng rãi trong việc gắn thẻ hình ảnh trên mạng xã hội, phân tích hình ảnh y khoa trong lĩnh vực chăm sóc sức khỏe, hay điều khiển xe tự lái trong ngành ô tô.

Hệ thống đề xuất
Sử dụng dữ liệu từ hành vi tiêu dùng trong quá khứ, thuật toán học máy giúp phát hiện các xu hướng của dữ liệu, từ đó phát triển chiến lược bán chéo hiệu quả hơn. Các hệ thống đề xuất này được các nhà bán lẻ trực tuyến sử dụng để đưa ra gợi ý sản phẩm phù hợp cho khách hàng trong quá trình mua hàng. Ví dụ, Spotify sử dụng hệ thống đề xuất để gợi ý các bài hát dựa trên lịch sử nghe của người dùng.
Giao dịch chứng khoán tự động
Các nền tảng giao dịch có tần suất cao do AI điều khiển có thể thực hiện hàng nghìn, thậm chí hàng triệu giao dịch mỗi ngày mà không cần sự can thiệp của con người. Điều này giúp tối ưu danh mục đầu tư và tối đa hóa lợi nhuận.
6. 5 thuật toán phổ biến trong Machine Learning
Dưới đây là các thuật toán Machine Learning phổ biến:

Mạng nơ-ron (Neural Networks)
Mạng nơ-ron mô phỏng cách hoạt động của não người, với rất nhiều nút xử lý liên kết với nhau. Mạng nơ-ron rất giỏi trong việc nhận diện mẫu và đóng vai trò quan trọng trong các ứng dụng như dịch ngôn ngữ, nhận diện hình ảnh, nhận diện giọng nói…
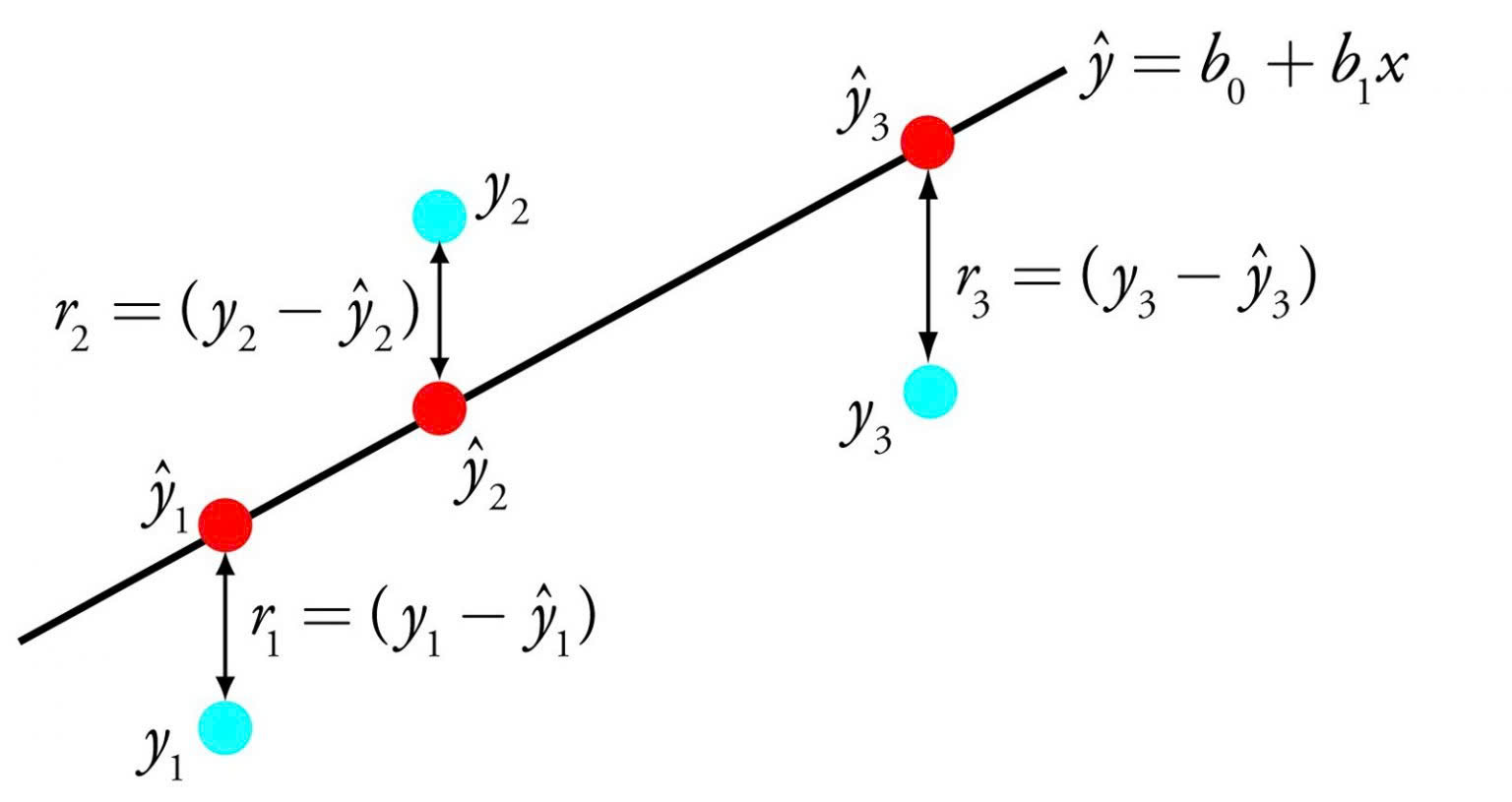
Hồi quy tuyến tính (Linear Regression)
Thuật toán này được sử dụng để dự đoán các giá trị số dựa trên mối quan hệ tuyến tính giữa các biến số khác nhau. Ví dụ, có thể dùng kỹ thuật này để dự đoán giá nhà dựa trên các dữ liệu quá khứ như diện tích, vị trí, số lượng phòng…
Hồi quy logistic (Logistic Regression)
Đây là thuật toán học có giám sát, dự đoán các biến đáp ứng phân loại, chẳng hạn như câu trả lời “có/không” cho các câu hỏi. Hồi quy logistic thường được sử dụng trong phân loại thư rác và kiểm soát chất lượng trên dây chuyền sản xuất.
Phân cụm (Clustering)
Sử dụng Học không giám sát, các thuật toán phân cụm có thể nhận diện các mẫu trong dữ liệu và nhóm chúng lại. Điều này có thể giúp các nhà khoa học tìm ra sự khác biệt giữa các mục dữ liệu mà con người có thể đã bỏ qua. Ví dụ: phân nhóm khách hàng dựa trên hành vi mua sắm.
Cây quyết định (Decision Trees)
Cây quyết định có thể được sử dụng để dự đoán giá trị số (hồi quy) và phân loại dữ liệu vào các nhóm. Cây quyết định sử dụng một chuỗi các quyết định được liên kết với nhau và có thể được biểu diễn bằng sơ đồ cây. Một ưu điểm của cây quyết định là dễ kiểm tra và xác minh.
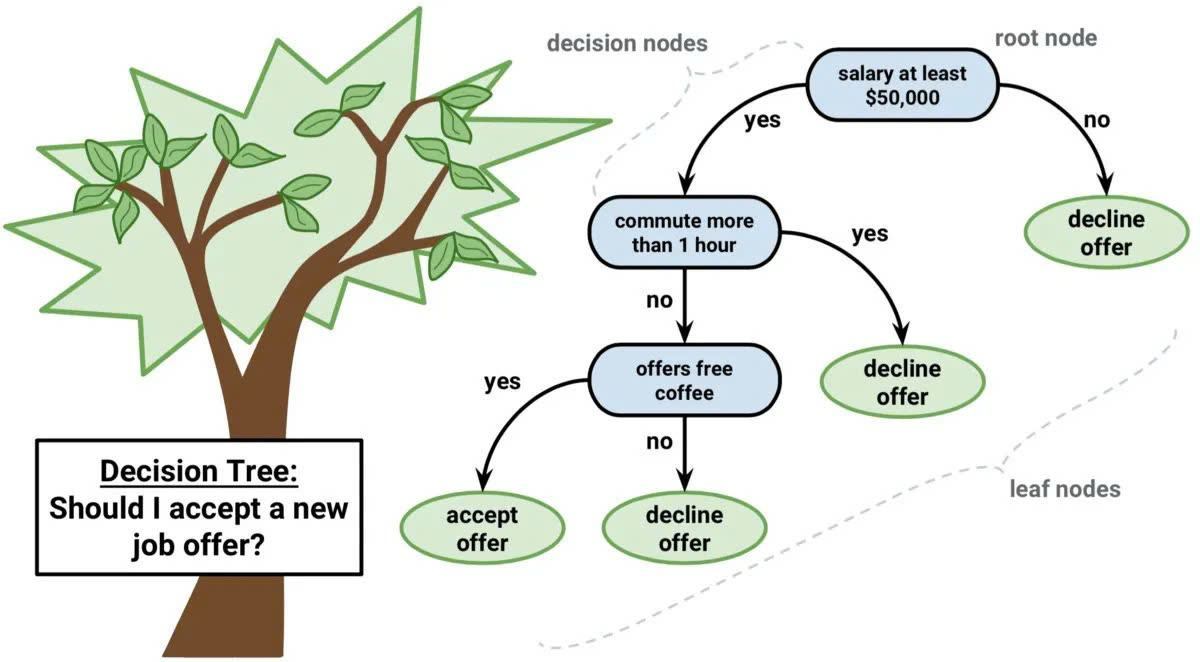
Ví dụ: xác định xem một khách hàng có nên được cấp tín dụng hay không dựa trên các yếu tố như thu nhập, lịch sử tín dụng, tình trạng công việc. Cây quyết định sẽ phân tích từng yếu tố và đưa ra quyết định dựa trên các quy tắc đã học từ dữ liệu quá khứ.
Rừng ngẫu nhiên (Random Forests)
Trong rừng ngẫu nhiên, thuật toán Machine Learning dự đoán một giá trị hoặc một danh mục bằng cách kết hợp kết quả từ nhiều cây quyết định khác nhau. Ví dụ: Dự đoán liệu một khách hàng có dừng sử dụng dịch vụ dựa trên các yếu tố như mức độ hài lòng, tần suất sử dụng, tương tác với bộ phận chăm sóc khách hàng. Rừng ngẫu nhiên sử dụng nhiều cây quyết định để đưa ra dự báo chính xác hơn.
>> Có thể bạn quan tâm: Công nghệ AI là gì? Các loại AI và ứng dụng của AI hiện nay
7. Kết luận
Machine Learning là một công nghệ cốt lõi trong thời đại số. Từ việc nhận diện giọng nói, phân loại dữ liệu, đến phát hiện gian lận và tối ưu hóa quy trình kinh doanh, Machine Learning đang dần trở thành một phần không thể thiếu trong cuộc sống.
Hy vọng, qua bài viết này, bạn đọc đã hiểu được Machine Learning là gì, cách thức hoạt động của chúng để nắm bắt được xu hướng và tận dụng tối đa lợi ích mà công nghệ này mang lại.
![]()





























